https://adventofcode.com/2022/day/15
Day 15 was one of my favorite Advent of Code puzzles so far. It has all of the qualities that I’ve come to enjoy in the Advent of Code puzzles: relatively simple to understand conceptually yet challenging to complete efficiently, multiple valid approaches, no obscure “tricks” required, and illustrates some interesting aspect of computing- in this case data sparsity.
The puzzle input involves “sensors” and “beacons” given by integer coordinates on an XY grid. Each sensor, which has known coordinates, reports the closest beacon and that beacon’s coordinates. The full problem description can be found at Advent of Code 2022 Day 15. If you’re not familiar with it, I suggest taking a look now because the full problem description is quite lengthy and I didn’t reproduce it all here. The sample toy-sized input file is shown below.
Sensor at x=2, y=18: closest beacon is at x=-2, y=15
Sensor at x=9, y=16: closest beacon is at x=10, y=16
Sensor at x=13, y=2: closest beacon is at x=15, y=3
Sensor at x=12, y=14: closest beacon is at x=10, y=16
Sensor at x=10, y=20: closest beacon is at x=10, y=16
Sensor at x=14, y=17: closest beacon is at x=10, y=16
Sensor at x=8, y=7: closest beacon is at x=2, y=10
Sensor at x=2, y=0: closest beacon is at x=2, y=10
Sensor at x=0, y=11: closest beacon is at x=2, y=10
Sensor at x=20, y=14: closest beacon is at x=25, y=17
Sensor at x=17, y=20: closest beacon is at x=21, y=22
Sensor at x=16, y=7: closest beacon is at x=15, y=3
Sensor at x=14, y=3: closest beacon is at x=15, y=3
Sensor at x=20, y=1: closest beacon is at x=15, y=3After using base python to parse the input file for the previous 14 puzzles the string manipulations were becoming a tedious, so I decided to use python’s regex library, re.regex. A simple split on non-digits seemed to do most of the work, but spoiler alert: this misses something in the input file that took me a LONG time to debug.
def parseInput(file): f = open(file) inp = f.read() inp = inp.split("\n") pairs = [] for txt in inp: x = re.split("\D+",txt) x_sensor = int(x[1]) y_sensor = int(x[2]) x_beacon = int(x[3]) y_beacon = int(x[4]) pairs.append([(x_sensor, y_sensor), (x_beacon, y_beacon)]) return (pairs)
Normally I find it’s a good idea to start attacking these puzzles by duplicating the example step by step using the toy example input, which is what I did here, using the basic naive approach of iterating through each beacon and populating a list of “not possible locations.” After initially forgetting to account for the positions that already have beacons, I quickly matched the example output for row 10. Easy peasy, what’s the catch?
def mapSensor(s, b): d = abs(s[0]-b[0]) + abs(s[1]-b[1]) covered = [] for i in range(d+1): for j in range(d-i+1): p1 = (s[0]+i, s[1]+j) p2 = (s[0]-i, s[1]+j) p3 = (s[0]-i, s[1]-j) p4 = (s[0]+i, s[1]-j) covered.append(p1) covered.append(p2) covered.append(p3) covered.append(p4) covered = [*set(covered)] return(covered) #main driver code pairs = parseInput("advent15_toy.txt") beacons = [] covered = [] for p in pairs: cov = mapSensor(p[0],p[1]) beacon = p[1] beacons.append(beacon) for i in cov: if ((i not in covered) and (i not in beacons)): covered.append(i) nob = 0 n = [] for c in covered: if c[1] == 10: n.append(c) nob +=1
The problem asks for the number of positions where a beacon can not exist, so I used list = [*set(list)] as an easy way to code removing the duplicates at the edges of the horizontal iteration. Creating a set for with every iteration is terribly slow and efficiency could be improved by not adding duplicated positions in the first place. However, when I got to the actual input file and discovered a sparsely populated space with dozens of sensors each millions of positions from the closest beacon, I realized I would need a new approach entirely.
As I started reworking the code to populate the “impossible beacon locations” in a single row at a time rather than the full 2d space, I realized that only ends of the range were important, since each of the millions of positions between were also “impossible beacon locations.” I just needed a way to avoid double counting when multiple sensors cause any given position to be an “impossible beacon location.” Consolidating overlapping ranges must be a common procedure, and a quick search to stack overflow yielded a snipped for that. Part 1 solved!
pairs = parseInput("advent15.txt") beacons = [] coveredRanges = [] y = 2000000 for p in pairs: cov = mapSensorRow(p[0],p[1], y) beacon = p[1] if beacon not in beacons: beacons.append(beacon) if cov != None: coveredRanges.append(cov) #merge overlapping range algorithm from stack overflow coveredRanges.sort(key=lambda interval: interval[0]) merged = [coveredRanges[0]] for current in coveredRanges: previous = merged[-1] if current[0] <= previous[1]: previous[1] = max(previous[1], current[1]) else: merged.append(current) #sum width of merged intervals n = 0 for r in merged: n += (r[1] - r[0] + 1) for b in beacons: if (b[1] == y) and (r[0] <= b[0] <= r[1]): n = n-1 #don't count if beacon is already there print(n, "impossible beacon locations in row",y)
In Part 2 we learn that for x and y between 0 and 4,000,000 there is only one possible position that could have a beacon given our input. The above code for a single row runs very quickly, so an obvious brute force solution is to check every row. For each row, if there are no possible positions between x = 0 and 4,000,000 the merged intervals will have exactly one interval, starting <0 and ending >4,000,000. (Unless the only possible location just happens to be an edge case x = 0 or x = 4,000,000 but that seems very unlucky and probably not the point of this puzzle so I’ll ignore that possibility for now.) For the one row with the single possible beacon position, the merged interval should contain exactly 2 sub-intervals of “impossible locations”, one to the left of beacon and one to the right.
I coded up a simple loop using my solution to part 1 to check the first few thousand rows and got…thousands of rows with multiple possible beacon locations?!?!? I went back and re-read the problem statement several times, it clearly states that there is only one possible beacon location in the whole space. It pains me to admit that I spent a long time debugging this one, checking for mistakes in open vs closed ranges, x vs y, and making plots to check against the toy example.
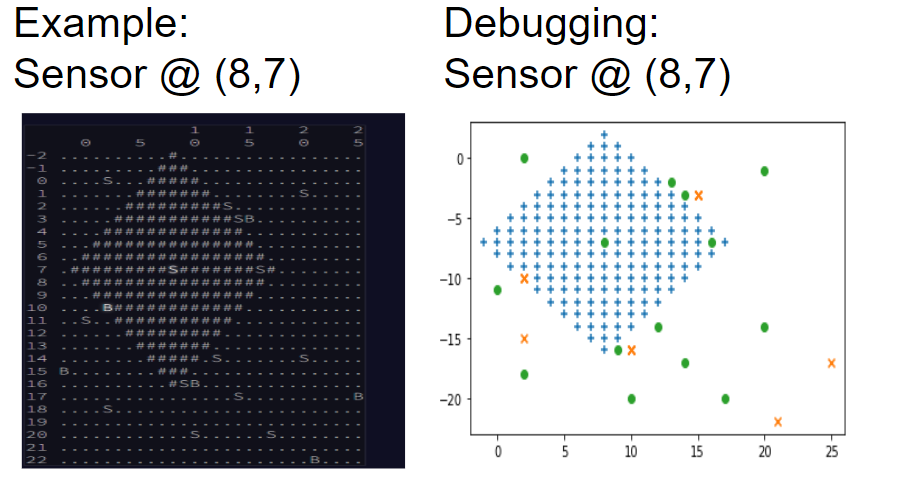
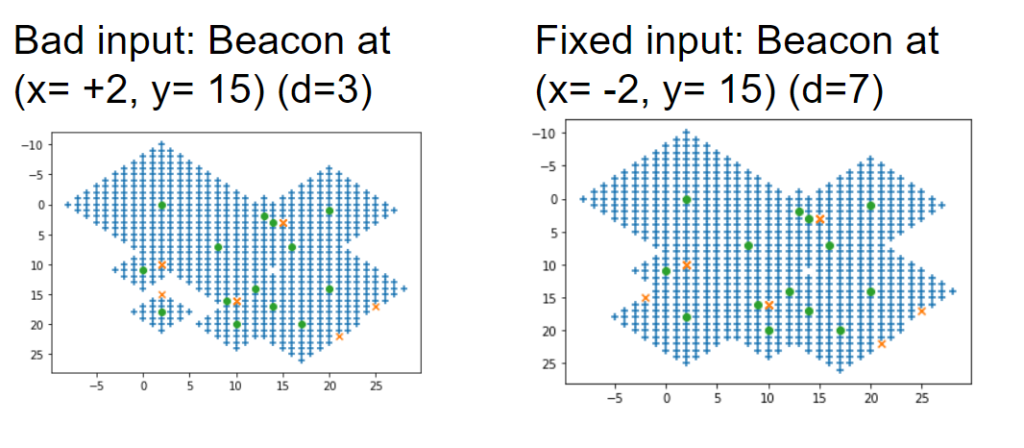
It was only after plotting the full example input that I realized something funny was going around the sensor at (x=2, y=15). The problem states that there is only a single possible location for the beacon within the space, but that sensor in the lower left has 2 or 3 rows of whitespace around it. Scrubbing the input file, I finally discovered that even thought the problem statement asked us to consider only positive locations for the “missing” beacon, the input beacons could in fact have negative coordinates. My quick and dirty regex parsing of the input file turned out to be a little too quick and a little too dirty.
#x = re.split("\D+",txt) # bad, missed negative inputs x = re.split("[^0-9-]+",txt) # corrected
After making the above correction to the input parsing function, success! For my input file, the missing beacon can only be at: y= 3,391,794 x= 3,103,499. Trival calculation of the “tuning factor” as described in the problem gives the final puzzle answer: 12,413,999,391,794. The final code below ran on my old laptop in ~70 seconds. Plenty of room for optimization, but hey it works.
One final thought: After staring at the plots above for a while, it occured to me that if I rotated the coordinate system 45 degrees, then the region “covered” by each sensor could be represented by four points defining a single square, and the solution could probably be computed very quickly by employing a method of consolidating “overlapping squares” in 2D instead of “overlapping ranges” for each row. Maybe a project for another day.
Final Day 16 Code:
import re def parseInput(file): f = open(file) inp = f.read() inp = inp.split("\n") pairs = [] for txt in inp: #x = re.split("\D+",txt) # bad, missed negative inputs x = re.split("[^0-9-]+",txt) # corrected x_sensor = int(x[1]) y_sensor = int(x[2]) x_beacon = int(x[3]) y_beacon = int(x[4]) pairs.append([(x_sensor, y_sensor), (x_beacon, y_beacon)]) return (pairs) def mapSensorRow(s, b, row): d = abs(s[0]-b[0]) + abs(s[1]-b[1]) sy = s[1] if abs(sy-row) <= d: j = d-abs(sy-row) leftx = (s[0] - j) rightx = (s[0] + j) return ([leftx,rightx]) def mergeRanges(cr): rng = cr.copy() rng.sort(key=lambda interval: interval[0]) m = [rng[0]] for current in rng: previous = m[-1] if current[0] <= previous[1] : previous[1] = max(previous[1], current[1]) else: m.append(current) return(m) #main driver code pairs = parseInput("advent15.txt") beacons = [] for p in pairs: beacon = p[1] if beacon not in beacons: beacons.append(beacon) result = [] y_max = 4000000 for y in range(0,y_max,1): coveredRanges = [] for p in pairs: cov = mapSensorRow(p[0],p[1], y) if cov != None: coveredRanges.append(cov) merged = mergeRanges(coveredRanges) if len(merged) > 1: result.append((y, merged)) break for r in result: print("The beacon can only be at: y=",r[0],"x=", r[1][0][1]+1) #1st x after end of fist interval print("Tuning factor:",(r[1][0][1]+1)*4000000 + r[0])